
With the exception of the assembly language instrumenter, the PAWB tools are machine independent or use existing programs that are available on most Unix machines. In order for the PAWB to be used on Sun4 computers, an assembly language instrumenter has been written for the Sparc computer architecture. The PAWB can now generate trace files on either the Sparc architecture or the Mips architecture. The rest of the PAWB, the PADL compiler and simulator, runs on most Unix systems.
The PAWB uses techniques to reduce the size of the trace files generated by the benchmark application. Even so, these files can become quite large for applications with large dynamic traces. To eliminate the need for the large tracefiles, the PAWB tools have been extended to allow for the concurrent generation of address traces and simulation.
As an example, an experiment was done using a matrix
multiply application. The program did a matrix multiply on two
square matrixes and produced a third result matrix. The data
presented in Figure 1 are for a matrix of size 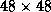 ,
however, similar results were observed for an
,
however, similar results were observed for an 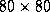 matrix.
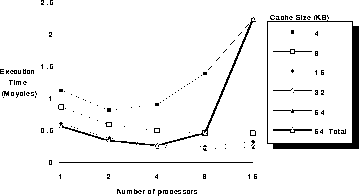
The results of the study show the execution time
vs. the number of processors for a cache size of 4, 8, 16, 32,
and 64 Kbyte. The caches have a 1 cycle access time
and used a simple write-invalidate coherence scheme.
The bus has a width of 4 bytes (1 word) and an access time of 7 cycles
for a read, 4 cycles for a write, and 1 cycle for an invalidate.
matrix.
The results of the study show the execution time
vs. the number of processors for a cache size of 4, 8, 16, 32,
and 64 Kbyte. The caches have a 1 cycle access time
and used a simple write-invalidate coherence scheme.
The bus has a width of 4 bytes (1 word) and an access time of 7 cycles
for a read, 4 cycles for a write, and 1 cycle for an invalidate.
Depending on the size of the cache, the execution time actually increased when 16 processors were used. There was a pronounced effect for the case of a relatively small 4Kbyte cache and to a smaller degree for caches of size 16, 32, and 64 Kbytes. The obvious cause of this increase in execution time for 16 processors is bus contention, but the more important questions are what caused the increase in bus contention and whether it is typical of other applications.
To answer these questions, we examined the algorithm used to perform a matrix multiply. For each element in the result matrix the following operation must be performed.

When one processor is used to do all of the computations for a given row of
the A matrix, it only accesses only one row of the B matrix, but it must
access the entire array of the C matrix. (The same would be true if one
processor did all of the work for one column of the A matrix.) Given that
each processor must access 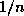 of one matrix and all of the other matrix,
the amount of data traffic for
of one matrix and all of the other matrix,
the amount of data traffic for  processors is
processors is 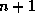 copies of an
copies of an 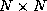 matrix. In the case of 16 processors, 17 matrixes are moved
from the main memory to the caches of the processors, rather then the two
matrixes moved for a uniprocessor, or roughly 8 times as much data traffic.
matrix. In the case of 16 processors, 17 matrixes are moved
from the main memory to the caches of the processors, rather then the two
matrixes moved for a uniprocessor, or roughly 8 times as much data traffic.
In addition to the extra data traffic, the average access time of each data
location is also increased. For the (7/4/1) bus model described above, a
uniprocessor would have an access time of 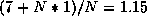 cycles/access.
In the case of 16 processors, a given processor will only operate on 1/n of
the total matrix, and therefore the access time for a location is
cycles/access.
In the case of 16 processors, a given processor will only operate on 1/n of
the total matrix, and therefore the access time for a location is 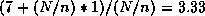 cycles/access, or roughly twice the access time.
cycles/access, or roughly twice the access time.
For this type of access pattern, where a large portion of the data must be used by all of the processors, there is a tradeoff between cache temporal locality and the number of processors. If the same size cache is used for each of the processors in the multiprocessor and uniprocessor, the degradation is obscured by the larger total cache size. To factor out the increase in size, the final line of Figure 1 connects points of an equal multiprocessor cache size of 64Kbytes. In this case, the four processor system with 16Kbyte caches on each processor performs better then an eight processor system with 4K caches on each processor. One conclusion is that without adequate cache support, increasing the number of processors is of marginal benefit.
The results of this study are being combined with the results of other benchmarks which exhibit different accessing patterns. The final result will give us a better understanding of the interrelationship between caches, number of processors and accessing patterns in shared-bus multiprocessors.
The PAWB is currently being used to study cache configurations and coherence protocols on shared bus multiprocessor systems. These studies concentrate on split-shared caches for processor-cache configurations constrained by space and limited pin-out.
Caches in a multiprocessor system increase performance be reducing the latency of memory accesses and by reducing the amount of traffic over the shared bus. Bus traffic caused by cache accesses can be broken into four categories of cache misses: compulsory misses, capacity misses, conflict misses, and coherency misses. Compulsory traffic is the initial transfer of memory locations from the main memory into the cache. Capacity traffic is caused by accessing more unique locations from the memory system than can be held in the cache. Conflict traffic is caused by multiple memory locations mapping onto a single location in the cache. Coherency traffic is required to make certain that different caches do not have different values for the same memory location.
Shared caches can be used to reduce some of the bus traffic associated with compulsory traffic, coherency traffic, and capacity traffic. It is possible for conflict traffic to increase in shared caches, but the savings in the other traffic should outweigh this possible increase.
The memory traffic caused by a processor in a multiprocessor system consists of accesses to the instruction stream, the private data stream of each processor, and the shared data stream to memory shared by all processors. Each of these streams has differing amounts of spatial and temporal locality. By using a separate cache for each type of data reference, it is possible to take advantage of the characteristics of each type of reference stream to reduce traffic.
The goal of the split-shared cache study is to determine how to share the split caches to best improve the performance of multiprocessor systems. The study will concentrate on small, on-chip caches used on a single chip multiprocessor to be used as a cluster on a larger multiprocessor system. Due to the pin limitation of a single chip multiprocessor, the study is concentrating on shared bus multiprocessors which require a single external bus.