

In the past year, we have obtained a number of results concerning the design of a massively-scalable dedicated processor for two and three-dimensional lattice-gas simulations capable of billions of cell updates per second (CUPS). The results will be reported in details in Fung F. Lee's doctoral dissertation [8]. Some of the concepts have been previously published in [12][9][11][10].
Many important simulation problems deal with complex physical systems with large numbers of degrees of freedom. All of the ten grand challenges such as fluid turbulence, pollution dispersion, and weather prediction, as listed in the report [7] prepared by the Office of Science and Technology Policy, fall into this category. Fluid dynamics provides an especially good case study of cellular automaton formulation of large complex physical systems because there are two rich and complementary ways to picture fluid motion. The microscopic picture of many simple molecules colliding rapidly with simple interactions coincides with our intuitive picture of dynamics on a cellular automaton, while the macroscopic picture of collective fluid motions based on considerations of conservation of mass, momentum and energy leads to the Navier-Stokes equations. Lattice gas models solving incompressible Navier-Stokes equations are selected as concrete examples of our study.
The kernel of a lattice gas simulation consists of updating the values of all lattice nodes (cells) by executing many repetitions of two alternating steps: particle collision and particle propagation. There are three major research issues involved in designing hardware support for lattice gas models, namely, collision mechanisms, propagation mechanisms and scalability. The most critical issue is the design of hardware mechanisms to support 3-D collision rules. On one hand, a full collision table implementation (requiring at least 384 Mbits) is relatively fast but very expensive, and thus hardly scalable in practice. On the other hand, algorithms that can use a reduced-size collision table (requiring 0.4 Mbits or more) execute relatively slowly. The best of both worlds would be a fast hardware collision unit that can use a reduced-size collision table. The second issue is the design of propagation mechanisms. When collision is fast, propagation becomes the bottleneck if nothing is done to improve it. In a system context, propagation implies data memory access and communication. Moreover, memory cost is likely to dominate the system cost. Therefore, the goal is to invent a set of mechanisms to support efficient memory access and utilization, and effective interprocessor communication. The third issue is scalability. A multiprocessor architecture is scalable if it achieves close to linear speedup as the number of processors dedicated to the task increases. (A massively-parallel machine is thus not necessarily massively-scalable.) Amdahl's Law says that if we want to achieve close to linear speedup with a large number of processors, only a small fraction of the original computation can be sequential. Therefore, performance of much less frequent operations such as handling of boundary conditions, input/output operations and statistics collections in a large scale multiprocessor architecture becomes a larger issue than it would be in an uniprocessor architecture.
We have shown that with appropriate hardware support it is feasible to design a dedicated processor with performance comparable to existing supercomputers, and how to put together a scalable SIMD machine, ALGE, containing from a few to thousands of these processors with close to linear speedup. The efficiency of the ALGE architecture derives from a set of new mechanisms.
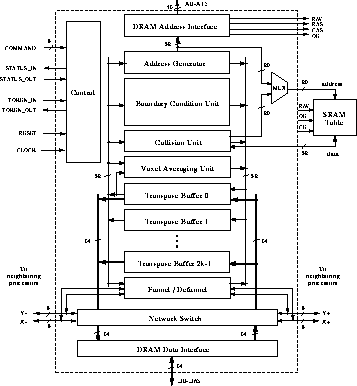
Figure 6: Block diagram of the ALGE processor
Based on group theory, two hardware collision rule reduction algorithms and architectures for use with reduced lookup tables have been developed. The isometric collision rule unit, which yields a moderate Reynolds coefficient for some fixed collision function, has been implemented in a field programmable gate array device with about 3000 gates. The general programmable collision rule unit, which works with a reduced collision table of 2.5 Mbits (or more if rest particles are added) can effectively compute all collision functions designed to yield higher Reynolds coefficient. Supporting propagation mechanisms include: virtual move as a zero buffering algorithm which gives the advantage of double buffering without the extra cost, multi-dimensional modulo adders for efficient address generation, transpose buffers for supporting the data structure optimized for efficient DRAM page-mode access, and a fast low-latency router for local nearest neighbor communication on a torus. Other supporting architectural mechanisms are extensive random number generators for flexible boundary conditions, support for statistics collection, and a scalable I/O mechanism.
An ALGE machine consists of a number of processor nodes connected in a two-dimensional torus. Each processor node contains an ALGE processor, a reduced collision table (SRAM) and data memory (DRAM). An ALGE processor is a VLSI circuit containing about half a million transistors, running at 20 MHz (see Figure 6). Most of the silicon area is spent on regular structures such as buffers and registers. The processor has multiple function units operating concurrently so that throughput is only limited by the data memory (page mode) cycle time. The processor has enough pins to support a collision table with 1 million entries of 32-bit words. The data memory is used to store the states of all the cells. A word of 64 bits can be accessed in one cycle. A typical local data memory has about 8 MB of DRAM. Simulation shows that with our chosen access sequence the page mode hit ratio can be high enough that the cell update rate per processor can be sustained at around 18 million cell updates per second (MCUPS). This per-processor performance compares very favorably with the performances of CRAY-2 (30 MCUPS) and CM-2 (45 MCUPS).